As some of you may already know there's this json-server project which aims to provide an easy way to create fake servers returning JSON responses over HTTP. This is very great project, but if you need something simpler that does not necessarily follow all of the REST rules, then you're out of luck.
For instance, if you use json-server with PUT/POST requests then underlying database will change.
really-simple-json-server, on the other hand, is an effort to create really simple JSON server. To actually show you how simple it is, let's have a look at example routes (example.json).
{
"/config": {"avatar_upstream_server": "172.17.42.42"},
"/u/1/friends": ["slavko", "asia", "agata", "zbyszek", "lucyna"],
"/u/2/friends": ["adam", "grzegorz"],
"/u/3/friends": [],
"/u/4/friends": ["slavko"]
}
Then, assuming all dependencies (see below) are installed it's all about starting a server:
$ ./server.py --port 1234 example.json
And we can start querying the server!
$ curl http://localhost:1234/config
{"avatar_upstream_server": "172.17.42.42"}
The project uses Python 3.5.1 along with aiohttp package. It is shipped with Docker image, so it's pretty easy to start hacking.
$ docker build -t szborows/python351_aiohttp .
$ docker run -it -v $PWD:/app:ro szborows/python351_aiohttp /bin/bash -c "/app/server.py --port 1234 /app/example.json"
czwartek, 17 marca 2016
środa, 16 marca 2016
ElasticSearch AWS cloud plugin problem connecting to Riak S3 endpoint without wildcard certs

curl -XPUT 'http://es.address.here:9200/_snapshot/s3_dev_backup?verify=false' -d '{
"type": "s3",
"settings": {
"access_key": "*****-***-**********",
"secret_key": "****************************************",
"bucket": "elastic",
"endpoint": "s3_cloud_front.address.here"
}
}'
As usual, in corporate reality, it didn't work. Instead, we got following exception.
Error injecting constructor, com.amazonaws.AmazonClientException: Unable to execute HTTP request: hostname in certificate didn't match: <elastic.s3_cloud_front.address.here> != <s3_cloud_front.address.here> OR <s3_cloud_front.address.here>
at org.elasticsearch.repositories.s3.S3Repository.<init>(Unknown Source)
while locating org.elasticsearch.repositories.s3.S3Repository
while locating org.elasticsearch.repositories.Repository
So apparently endpoint certificate (self signed one, btw) wasn't prepared in such a way that both e.g. endpoint.address and subdomain.endpoint.address would match. In other words it wasn't wildcard certificate bound to the endpoint domain name.
We decided to debug with StackOverflow (it's common technique nowadays, isn't it :D?). After trying numerous solutions like disabling certificate check using java flags or even using so-called java agents to hijack default hostname verifier we ran out of ideas how to elegantly solve the problem. And here comes our ultimate hack - hijacking Apache httpclient library.
The idea behind the hack is simple - re-compile httpclient library with one small modification - put premature return statement at the very top of hostname verification function. The function, where the change should be made is as follows.
org.apache.http.conn.ssl.SSLSocketFactory.verifyHostname(SSLSocketFactory.java:561)
One thing to remember is that the return statement must be wrapped with some silly if statement (e.g. if (1 == 1)), so the compiler won't complain about unreachable code below. It's funny that java compiler doesn't eliminate such trivial things, but in this particular scenario it was a feature rather than a bug. If the verifyHostname method wasn't throwing an exception then the modification would be even simpler - just an return statement.
The change is trivial, so I'm not including it here. The last step is to replace httpclient jar in AWS cloud plugin with raped one and we're done. No more complains about SSL hostnames.
wtorek, 8 marca 2016
Mini REST+JSON benchmark: Python 3.5.1 vs Node.js vs C++
Some time ago at Nokia I voluntarily developed a search engine tailored for internal resources (Windows shares, intranet sites, ldap directories, etc..) - NSearch. Since then few people helped me to improve it so it became unofficial "search that simply works". However, as you can image, this was purely a side-by project so I didn't pay attention to quality of the code much (I'd love to do so, but cruel time didn't permit :/). As a result during passing months a lot of technical debt was borrowed.

Recently we came to a conclusion that it's enough. We agreed that the backend of the service is going to be first in line. Because all of it was about to be rewritten we thought that maybe it's a perfect time to evaluate other technologies. Currently it's using Python2.7 + Django + Gunicorn. We consider going to either Node.js with Express 4, Python3 with aiohttp or C++. Maybe other language would be even a better match? However, we don't program in any other languages on a daily basis...
In this post I'd like to show you results of my very simple evaluation of performance of these three technologies along with some findings.
Technical facts
I prepared two JSON objects used for two following benchmarks. The first was simple {"hello": "world!"} and the second was extracted directly from NSearch and connsisted of about 10k of characters, but I can't include it here. For the C++ I used Restbed framework and jsoncpp library, just to have anything with normal URL path support (otherwise results wouldn't be reliable at all).

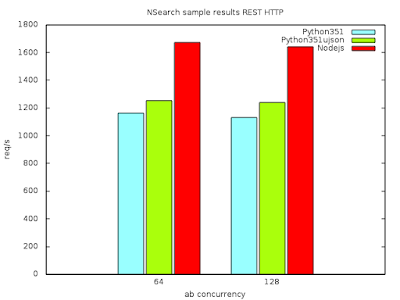
First benchmark - conclusions:
Second benchmark - conclusions:
(I excluded C++ because of convenience of filling JSON object)
Why Python is so slow and Node.js much faster?
Python is interpreted language. This is main reason why it's so slow. Why it's not the case with Node.js? Because Node.js uses V8 - JavaScript interpreter - which has built-in JS JITter. JITter means Just-In-Time compiler which can speed up execution of a program by order of magnitude.
Can Python be faster? Yes!
There's also Python interpreter with built-in JITter - PyPy. Unfortunately it doesn't support 3.5.1 version of Python yet.

Recently we came to a conclusion that it's enough. We agreed that the backend of the service is going to be first in line. Because all of it was about to be rewritten we thought that maybe it's a perfect time to evaluate other technologies. Currently it's using Python2.7 + Django + Gunicorn. We consider going to either Node.js with Express 4, Python3 with aiohttp or C++. Maybe other language would be even a better match? However, we don't program in any other languages on a daily basis...
In this post I'd like to show you results of my very simple evaluation of performance of these three technologies along with some findings.
Technical facts
- everything was tested on machine with Intel E5-2680 v3 CPU and 192 GBs of RAM running on RHEL-7.1 OS,
- applications were run from under Docker containers, so there might be some overhead introduced by libcontainer, libnetwork, etc.
- ab was used for benchmarking with 1M of requests with different concurrency settings
- max timeout was set to 1 second
I prepared two JSON objects used for two following benchmarks. The first was simple {"hello": "world!"} and the second was extracted directly from NSearch and connsisted of about 10k of characters, but I can't include it here. For the C++ I used Restbed framework and jsoncpp library, just to have anything with normal URL path support (otherwise results wouldn't be reliable at all).


First benchmark - conclusions:
- all solutions are asynchronous and event based and they're using event loops. otherwise it wouldn't be the case that 512 concurrent users can be served with max timeout set to 1 second
- starting from 192 concurrent users amount of requests per second starts to decrease slightly
- Python is more than two times slower than Node.js
- C++ is more than two times faster than Node.js
Second benchmark - conclusions:
(I excluded C++ because of convenience of filling JSON object)
- the gap between Python and Node.js is much smaller when bigger JSON is in question
- apparently starting to handle a request in Python is slow, at least compared to Node.js
- replacing json.dumps with ujson.dumps increases Python performance by about 5%
- Node.js performance drops drastically when bigger JSON is used - from over 5k of requests per second to about 1700!
- Python's drop is not that drastic - from about 1700 to 1200 requests per second. It means that when the handling is ongoing, Python is not slowing down.
Why Python is so slow and Node.js much faster?
Python is interpreted language. This is main reason why it's so slow. Why it's not the case with Node.js? Because Node.js uses V8 - JavaScript interpreter - which has built-in JS JITter. JITter means Just-In-Time compiler which can speed up execution of a program by order of magnitude.
Can Python be faster? Yes!
There's also Python interpreter with built-in JITter - PyPy. Unfortunately it doesn't support 3.5.1 version of Python yet.
poniedziałek, 7 marca 2016
CMake disservice: project command resets CMAKE_EXE_LINKER_FLAGS
tl;dr at the bottom
CMake version: 3.3.2
I think that everyone can agree that in the world of programming there are a lot of frustrating and irritating things. Some of them are less annoying, some are more and they are appearing basically at random resulting in a waste of time. Personally I think the most depressing and worst thing that one can encounter is implicit and silent weird side effects. I was hit by such a side effect today at work and would like to write about is as well as (possibly) help future Googlers.

So let me go straight to the topic. Recently platform software that is used in one of our medium-size C++ projects has changed and started to require some additional shared library. Our project stopped to compile because this new dependency wasn't listed in link libraries. We thought that the fix will be as simple as appending one item to the list, but we were proven wrong. Apparently this new shared library was linked with several other shared objects and this complicated things a little bit.
So the linker could be potentially satisfied just with the dependency itself, but this is not what happens (at least with GNU ld). The linker tries to minimize a chance that some symbols will be unresolved in run-time, so it checks whether all of the symbols are in place, even those coming from the dependent shared object! This effectively means that the linker will go through all of the unresolved symbols in every shared object and check them, regardless whether it's needed or not. I think that this is a nice feature, but there's one caveat - the linker doesn't actually know where to look for sub-dependent shared objects. This must be explicitly specified.
And here comes the unintuitive thing - rpath-link. Let me start with rpath, though. When the program is built and then run, the run-time linker (a.k.a loader) will look for all libraries linked to it and map them to the process memory space. There is specific order where the linker will look for the libraries: it will honor rpath in the first place, then it will consider LD_LIBRARY_PATH environment variable and finally standard system places. The rpath-link is similar to rpath, but... it's related to link-time and not run-time (this is this not intuitive part, or is it?). The linker will utilize rpath-link to look for sub-dependent libraries (Fig. 1).

Okay, but what this all has to do with CMake?
In CMake if you want to provide linker flags you need to utilize CMAKE_*_LINKER_FLAGS family of variables. And it's working perfectly fine unless you need to provide custom toolchain and sysroot (e.g. you are doing crosscompilation). Traditional way to provide custom toolchain with CMake is to pass -DCMAKE_TOOLCHAIN_FILE to cmake command. CMake will then process the toolchain file before CMakeLists.txt allowing to change compilers, sysroots etc. It's worth mentioning here that toolchain file will be processed before project command.
As it turned out, it works flawlessly for all of the variables like CMAKE_CXX_FLAGS etc. but CMAKE_*_LINKER_FLAGS variables. It took us some time to discover that... call to project command actually resets value of the CMAKE_*_LINKER_FLAGS variables. What a pesky side effect! After some digging I've found the culprit in file Modules/CMakeCommonLanguageInclude.cmake:
# executable linker flags
set (CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS_INIT}"
CACHE STRING "Flags used by the linker.")
As you can imagine CMAKE_EXE_LINKER_FLAGS_INIT is not set to anything reasonable. So the result of this is that CMake doesn't care what you had in CMAKE_*_LINKER_FLAGS. It simply drops what've been there and replaces it with empty string. In one word - disservice.
This is not end of the story, though. CMake had one more surprise for us - to our misfortune. As some of you know, there's this useful variable_watch command available in recent versions of CMake. It allows to watch variable for all reads and writes. At the beginning we were sure that something within our build system is changing our CMAKE_EXE_LINKER_FLAGS so we used variable_watch to figure out what's going on. However it didn't indicate any modification. In the end it turned out that it does not signal anything that happens under the bonnet (e.g. it ignores what project command does to observed variable). This is a joke!

Building systems like CMake is definitely not an easy task. Especially if you are targeting lots of users and support lot of scenarios ranging from compiling simple one-file project to cross-compiling huge project with huge amount of dependencies. In our case several things contributed to the final effect, but I wouldn't say that custom linker flags in a toolchain files is a corner case. I think it should be definitely fixed some day.
Or maybe this is a feature and I'm the dumb one?
tl;dr:
cmake_minimum_required(VERSION 3.0)
set(CMAKE_EXE_LINKER_FLAGS "-Wl,-rpath-link=/opt/lib64")
project(GreatProject)
# tada! CMAKE_EXE_LINKER_FLAGS is now empty.
CMake version: 3.3.2
I think that everyone can agree that in the world of programming there are a lot of frustrating and irritating things. Some of them are less annoying, some are more and they are appearing basically at random resulting in a waste of time. Personally I think the most depressing and worst thing that one can encounter is implicit and silent weird side effects. I was hit by such a side effect today at work and would like to write about is as well as (possibly) help future Googlers.

So let me go straight to the topic. Recently platform software that is used in one of our medium-size C++ projects has changed and started to require some additional shared library. Our project stopped to compile because this new dependency wasn't listed in link libraries. We thought that the fix will be as simple as appending one item to the list, but we were proven wrong. Apparently this new shared library was linked with several other shared objects and this complicated things a little bit.
So the linker could be potentially satisfied just with the dependency itself, but this is not what happens (at least with GNU ld). The linker tries to minimize a chance that some symbols will be unresolved in run-time, so it checks whether all of the symbols are in place, even those coming from the dependent shared object! This effectively means that the linker will go through all of the unresolved symbols in every shared object and check them, regardless whether it's needed or not. I think that this is a nice feature, but there's one caveat - the linker doesn't actually know where to look for sub-dependent shared objects. This must be explicitly specified.
And here comes the unintuitive thing - rpath-link. Let me start with rpath, though. When the program is built and then run, the run-time linker (a.k.a loader) will look for all libraries linked to it and map them to the process memory space. There is specific order where the linker will look for the libraries: it will honor rpath in the first place, then it will consider LD_LIBRARY_PATH environment variable and finally standard system places. The rpath-link is similar to rpath, but... it's related to link-time and not run-time (this is this not intuitive part, or is it?). The linker will utilize rpath-link to look for sub-dependent libraries (Fig. 1).

Figure. 1. Flags for project dependencies and dependencies' dependencies (sub-dependencies)
Okay, but what this all has to do with CMake?
In CMake if you want to provide linker flags you need to utilize CMAKE_*_LINKER_FLAGS family of variables. And it's working perfectly fine unless you need to provide custom toolchain and sysroot (e.g. you are doing crosscompilation). Traditional way to provide custom toolchain with CMake is to pass -DCMAKE_TOOLCHAIN_FILE to cmake command. CMake will then process the toolchain file before CMakeLists.txt allowing to change compilers, sysroots etc. It's worth mentioning here that toolchain file will be processed before project command.
As it turned out, it works flawlessly for all of the variables like CMAKE_CXX_FLAGS etc. but CMAKE_*_LINKER_FLAGS variables. It took us some time to discover that... call to project command actually resets value of the CMAKE_*_LINKER_FLAGS variables. What a pesky side effect! After some digging I've found the culprit in file Modules/CMakeCommonLanguageInclude.cmake:
# executable linker flags
set (CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS_INIT}"
CACHE STRING "Flags used by the linker.")
As you can imagine CMAKE_EXE_LINKER_FLAGS_INIT is not set to anything reasonable. So the result of this is that CMake doesn't care what you had in CMAKE_*_LINKER_FLAGS. It simply drops what've been there and replaces it with empty string. In one word - disservice.
This is not end of the story, though. CMake had one more surprise for us - to our misfortune. As some of you know, there's this useful variable_watch command available in recent versions of CMake. It allows to watch variable for all reads and writes. At the beginning we were sure that something within our build system is changing our CMAKE_EXE_LINKER_FLAGS so we used variable_watch to figure out what's going on. However it didn't indicate any modification. In the end it turned out that it does not signal anything that happens under the bonnet (e.g. it ignores what project command does to observed variable). This is a joke!

Building systems like CMake is definitely not an easy task. Especially if you are targeting lots of users and support lot of scenarios ranging from compiling simple one-file project to cross-compiling huge project with huge amount of dependencies. In our case several things contributed to the final effect, but I wouldn't say that custom linker flags in a toolchain files is a corner case. I think it should be definitely fixed some day.
Or maybe this is a feature and I'm the dumb one?
tl;dr:
cmake_minimum_required(VERSION 3.0)
set(CMAKE_EXE_LINKER_FLAGS "-Wl,-rpath-link=/opt/lib64")
project(GreatProject)
# tada! CMAKE_EXE_LINKER_FLAGS is now empty.
Subskrybuj:
Posty (Atom)